
Table des matières
La semaine dernière, j’ai trouvé un post intéressant sur Search Engine Land. Il m’a inspiré une recherche pour voir si je pouvais trouver un brevet de Google qui pourrait y être lié :
Google propose des recherches basées sur l’activité récente des utilisateurs
J’ai essayé de reproduire les suggestions de recherche qui étaient présentées à l’auteur de l’article Search Engine Land, mais Google ne m’a pas renvoyé ces suggestions. Il se peut que Google fasse des expériences avec un nombre limité de chercheurs plutôt que de montrer ces résultats à tout le monde. J’ai trouvé un brevet qui parle de suggestions de recherche similaires.
Lorsque Google affiche une suggestion de recherche sur un élément que vous avez peut-être déjà recherché dans le passé, cette suggestion est probablement liée à un brevet sur lequel j’ai déjà écrit, Autocomplétion à l’aide des données d’interrogation précédemment soumises.
J’ai écrit que ce brevet était mis à jour dans un brevet de continuation, mais je n’ai pas donné beaucoup de détails sur son fonctionnement : Comment Google prévoit la mise à jour des suggestions de requêtes automatiques.
Il y a quelques parties intéressantes sur la façon dont les suggestions de recherche sont identifiées et classées, ce qui m’a inspiré à écrire ce billet.
Suggestions de recherche basées sur des données de requête soumises antérieurement
La description de ce brevet commence par nous dire qu’il s’agit d’un brevet : « l’utilisation des données de requête précédemment soumises pour anticiper la demande de recherche d’un utilisateur ».
Cela montre bien que Google a une longue mémoire et qu’il se souvient de beaucoup de choses sur ce que quelqu’un pourrait chercher.
Cette description de brevet comprend également un grand nombre des hypothèses que les ingénieurs de recherche font au sujet des chercheurs (ce qui constitue souvent une raison intéressante de lire les brevets). Voici quelques éléments de ce brevet qui méritent réflexion :
Les moteurs de recherche Internet visent à identifier les documents ou autres éléments qui répondent aux besoins d’un utilisateur et à présenter les documents ou éléments de la manière la plus utile pour l’utilisateur. Une telle activité implique souvent une bonne dose de lecture de l’esprit, en se basant sur divers indices de ce que veut l’utilisateur. Certains indices peuvent être spécifiques à l’utilisateur. Par exemple, le fait de savoir qu’un utilisateur fait une demande à partir d’un appareil mobile et de connaître l’emplacement de l’appareil peut donner de bien meilleurs résultats de recherche pour cet utilisateur.
Les indices sur les besoins d’un utilisateur peuvent également être plus généraux. Par exemple, les résultats de recherche peuvent avoir une importance élevée, ou une pertinence inférée, si un certain nombre d’autres résultats de recherche y sont liés. Si les résultats liés sont eux-mêmes très pertinents, alors les résultats liés peuvent avoir une pertinence particulièrement élevée. Une telle approche de la détermination de la pertinence peut se baser sur l’hypothèse que, si les auteurs de pages web estiment qu’un autre site web est suffisamment pertinent pour être lié, alors les chercheurs trouveront également le site particulièrement pertinent. En bref, les auteurs de pages web « votent » la pertinence des sites.
D’autres entrées diverses peuvent être utilisées à la place ou en plus de ces techniques pour déterminer et classer les résultats de recherche. Par exemple, les réactions des utilisateurs à des résultats de recherche particuliers ou à des listes de résultats de recherche peuvent être mesurées, de sorte que les résultats sur lesquels les utilisateurs cliquent souvent seront mieux classés. L’hypothèse générale d’une telle approche est que les utilisateurs sont souvent les meilleurs juges de la pertinence, de sorte que s’ils sélectionnent un résultat de recherche particulier, il est susceptible d’être pertinent, ou du moins plus pertinent que les autres solutions présentées.
Un résumé du processus de suggestions de recherche basé sur les demandes soumises précédemment
Comme la plupart des brevets, la description de celui-ci commence par une section récapitulative qui donne un aperçu du fonctionnement du procédé défini dans le brevet. Elle est suivie d’une section « Description détaillée » qui va plus en profondeur et fournit des détails sur le fonctionnement de la recherche sur Google, et sur la manière dont certains aspects spécifiques de la recherche sur Google alimentent ce processus de suggestion de recherche. Lisez donc comment des suggestions de recherche peuvent être fournies sur la base de requêtes d’utilisateurs qui ont été recherchées précédemment, puis lisez l’explication plus détaillée, qui va bien au-delà de la saisie automatique.
Dans la partie sommaire de la description du brevet, on nous explique comment le brevet peut répondre à ces hypothèses :
Lorsqu’on anticipe les demandes de recherche des utilisateurs, la réponse à l’algorithme de ce brevet peut impliquer certaines méthodes de traitement des informations de la requête. Il s’agit notamment des méthodes suivantes
- Réception d’informations sur un système de serveur, avec une partie de la requête d’un chercheur
- Obtention d’un ensemble de requêtes prévues concernant la partie de la requête du chercheur basée sur la requête et les données indicatives du chercheur par rapport aux requêtes précédemment soumises
- Fournir l’ensemble des requêtes prévues au chercheur
Le brevet souligne également les caractéristiques supplémentaires impliquées dans le processus telles que l’obtention des requêtes prévues, y compris l’ordre de l’ensemble des requêtes prévues en fonction de critères de classement.
Ces critères de classement peuvent être basés sur les données indiquant le comportement du chercheur par rapport aux requêtes soumises précédemment.
Les données relatives au comportement du chercheur par rapport aux demandes précédemment soumises peuvent inclure
- Cliquez sur les données
- Données spécifiques au lieu
- Données spécifiques à la langue
- Autres types de données similaires
Le brevet souligne les avantages suivants de suivre le processus décrit dans le brevet :
Un assistant de recherche reçoit les informations d’un demandeur de recherche, avant qu’un chercheur ne saisisse complètement la requête.
Les informations associées aux recherches précédentes de l’utilisateur (ou des utilisateurs) (telles que les données de clic associées aux résultats de la recherche) sont collectées. À partir des informations sur la requête et des informations sur la recherche précédente, un ensemble de requêtes prédites est produit et fourni au demandeur de la recherche pour présentation.
Le brevet peut être consulté à l’adresse suivante :
Autocomplétion à l’aide des données d’interrogation précédemment soumises
Inventeurs : Michael Herscovici, Dan Guez, et Hyung-Jin Kim
Cessionnaire : Google Inc.
Brevet américain : 9,740,780
Accordée : 22 août 2017
Déposé : 1er décembre 2014
Résumé
Une méthode mise en œuvre par ordinateur pour le traitement des informations de requête comprend la réception des informations de requête sur un système serveur. Les informations de la requête comprennent une partie de la requête d’un demandeur de recherche. La méthode comprend également l’obtention d’un ensemble de prédictions relatives à la partie de la requête du demandeur, basées sur la partie de la requête du demandeur et sur des données indiquant le comportement du demandeur par rapport aux requêtes précédemment soumises. La méthode comprend également la fourniture de l’ensemble des requêtes prévues au demandeur de recherche.
Analyse du classement et sélection des suggestions de recherche sur la base des données de la requête précédente
La section « Description détaillée » de ce brevet de suggestions de recherche fournit une analyse approfondie de la recherche sur Google.
La pertinence et les liens de retour, ainsi qu’un moteur de modification du classement, conduisent au classement de nombreux résultats sur Google
Ce brevet met en évidence certains aspects du fonctionnement de la recherche sur Google. Il nous dit cela :
-
- L’objectif du procédé dans le brevet est d' »améliorer la pertinence des résultats obtenus en soumettant des requêtes de recherche ».
- Il décrit le classement des documents pour une requête comme quelque chose qui peut être « effectué en utilisant des techniques traditionnelles pour déterminer un score de recherche d’information (IR) pour les documents indexés en vue d’une requête donnée ». Et la pertinence d’un document particulier par rapport à un terme de recherche peut être déterminée par une technique, telle que l’examen du niveau général des rétroliens vers un document contenant des correspondances pour un terme de recherche qui peut être utilisé pour déduire la pertinence d’un document. Comme l’indique le brevet :
En particulier, si un document est lié (par exemple, est la cible d’un hyperlien) à de nombreux autres documents pertinents (par exemple, des documents qui contiennent également des correspondances pour les termes de recherche), on peut en déduire que le document cible est particulièrement pertinent. Cette déduction peut être faite parce que les auteurs des documents de pointage pointent vraisemblablement, pour la plupart, vers d’autres documents qui sont pertinents pour leur public.
- On nous donne plus de détails sur le fait que certains résultats sont encore plus pertinents que ceux avec des liens de retour. C’est ce qu’on nous dit :
Si les documents de pointage sont à leur tour la cible de liens provenant d’autres documents pertinents, ils peuvent être considérés comme plus pertinents, et le premier document peut être considéré comme particulièrement pertinent parce qu’il est la cible de documents pertinents (voire très pertinents). Une telle technique peut être le déterminant de la pertinence d’un document ou l’un des multiples déterminants. Cette technique est illustrée dans certains systèmes qui traitent un lien d’une page web à une autre comme une indication de la qualité de cette dernière, de sorte que la page présentant le plus grand nombre de ces indicateurs de qualité est mieux notée que les autres. Des techniques appropriées peuvent également être utilisées pour identifier et éliminer les tentatives de faux votes afin d’augmenter artificiellement la pertinence d’une page.
- Il existe une autre étape qui pourrait potentiellement rendre certains résultats encore plus pertinents et qui implique ce que l’on appelle un moteur de modification de rang :
Pour améliorer encore ces techniques traditionnelles de classement des documents, le moteur de classement peut recevoir un signal supplémentaire d’un moteur de modification du classement pour l’aider à déterminer un classement approprié des documents. Le moteur de modification du classement fournit un ou plusieurs modèles antérieurs, ou une ou plusieurs mesures de pertinence pour les documents basées sur un ou plusieurs modèles antérieurs, qui peuvent être utilisés par le moteur de classement pour améliorer le classement des résultats de recherche fournis à l’utilisateur. En général, un modèle antérieur représente une probabilité de sélection des résultats d’un document en fonction des valeurs de plusieurs caractéristiques sélectionnées, comme décrit plus loin. Le moteur de modification du classement peut effectuer une ou plusieurs des opérations décrites ci-dessous pour générer un ou plusieurs modèles antérieurs, ou une ou plusieurs mesures de pertinence basées sur un ou plusieurs modèles antérieurs.
Il s’agit d’une description plus détaillée du classement que ce que nous voyons habituellement sur Google. La section ci-dessus fait référence à un moteur de modification du classement qui sera décrit plus en détail plus loin dans cet article
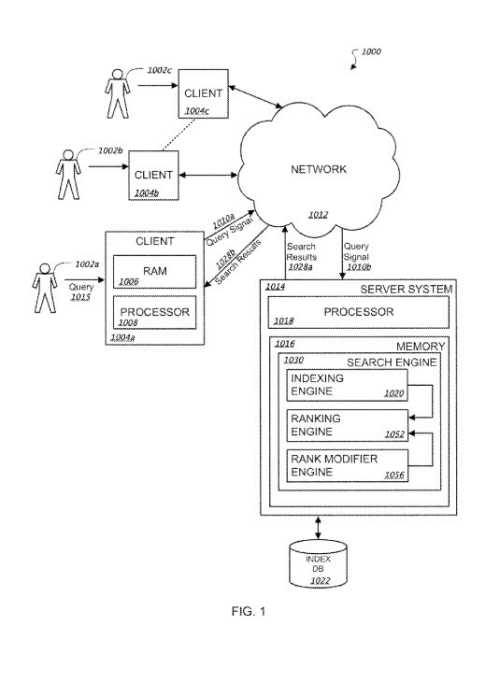
Moteur d’indexation, de notation, de classement et de modification du classement
Le système de recherche d’informations de ce brevet comprend un certain nombre d’éléments différents :
- Moteur d’indexation
- Moteur de notation
- Moteur de classement
- Moteur de modification du rang
Le moteur d’indexation peut fonctionner comme décrit dans la section ci-dessus pour le moteur d’indexation.
Moteur de notation
En outre, un moteur de notation peut fournir des notes pour les résultats des documents en fonction de nombreuses caractéristiques différentes, notamment
- Des fonctionnalités basées sur le contenu qui relient une requête à des résultats de documents
- des caractéristiques indépendantes de la recherche qui indiquent généralement la qualité des résultats des documents
Les fonctionnalités basées sur le contenu comprennent des aspects du format du document, tels que les correspondances de requête avec le titre ou le texte d’ancrage dans une page HTML (HyperText Markup Language).
Les fonctionnalités indépendantes de la recherche peuvent inclure des aspects de référencement de documents, tels qu’un classement du document ou du domaine.
En outre, les fonctions particulières utilisées par le moteur de notation peuvent être réglées, afin d’ajuster les différentes contributions des caractéristiques au score IR final, à l’aide de processus automatiques ou semi-automatiques.
Moteur de classement
Un moteur de classement peut produire un classement des résultats de recherche de documents à afficher pour un chercheur en fonction des scores IR reçus du moteur de notation et éventuellement d’un ou plusieurs signaux du moteur de modification du classement.
Un élément de suivi peut être utilisé pour enregistrer des informations sur les sélections individuelles des résultats de recherche présentés dans le classement. Le brevet décrit comment les sélections peuvent être suivies à l’aide de javascript, d’un système de proxy ou d’un plugin de barre d’outils :
Par exemple, le composant de suivi peut être un code JavaScript intégré dans un classement de pages web qui identifie les sélections (clics) de l’utilisateur des résultats des documents individuels et qui identifie également le moment où l’utilisateur revient à la page de résultats, indiquant ainsi le temps passé par l’utilisateur à visualiser le résultat du document sélectionné. Dans d’autres applications, le composant de suivi peut être un système proxy par lequel les sélections de l’utilisateur des résultats des documents sont acheminées, ou le composant de suivi peut inclure un logiciel préinstallé sur le client (par exemple, un plug-in de barre d’outils pour le système d’exploitation du client). D’autres mises en œuvre sont également possibles, par exemple en utilisant une fonction d’un navigateur web qui permet d’inclure une balise ou une directive dans une page, qui demande au navigateur de se reconnecter au serveur avec un ou plusieurs messages concernant le(s) lien(s) cliqué(s) par l’utilisateur.
Ces informations de sélection peuvent également être enregistrées, ce qui pourrait permettre de les saisir pour chaque sélection :
- la requête (Q)
- le document (D)
- l’heure (T) sur le document
- la langue (L) utilisée par l’utilisateur
- le pays (C) où l’utilisateur est probablement situé (par exemple, en fonction du serveur utilisé pour accéder au système IR).
D’autres informations peuvent également être enregistrées sur les interactions d’un chercheur avec les classements présentés :
- Informations négatives, telles que le fait qu’un résultat de document a été présenté à un utilisateur, mais n’a pas été cliqué
- Position(s) du/des clic(s) dans l’interface utilisateur
- Score IR des résultats cliqués
- Score IR de tous les résultats affichés avant le résultat cliqué
- Titres et extraits montrés à l’utilisateur avant le résultat cliqué
- Le cookie de l’utilisateur
- L’âge du cookie
- Adresse IP (protocole Internet)
- Agent utilisateur du navigateur
- Etc
Il est possible d’obtenir plus d’informations (comme décrit dans ce post ci-dessous) sur la construction d’un modèle antérieur.
Moteur de modification du rang
Des informations similaires (par exemple, les scores IR, la position, etc.) peuvent être enregistrées pour une session entière, ou pour plusieurs sessions d’un chercheur, y compris éventuellement l’enregistrement de chaque clic qui se produit avant et après un clic en cours.
Les informations qui sont stockées dans les journaux de sélection des résultats peuvent être utilisées par le moteur de modification du classement pour générer un ou plusieurs signaux à destination du moteur de classement.
Les informations stockées dans les journaux de sélection des résultats de recherche ainsi que les informations recueillies par la composante de suivi peuvent également être accessibles par un assistant de recherche, qui est également une composante du système de recherche d’informations.
En plus de recevoir des informations de ces composants, l’assistant de recherche peut également surveiller la saisie d’une requête de recherche par un utilisateur.
À la réception d’une requête de recherche partielle, la requête ainsi que les informations (par exemple, les données de clic) du composant de suivi et le(s) journal(s) de sélection des résultats peuvent être utilisés pour prévoir la requête complète envisagée par un chercheur.
Sur la base de ces informations, les prédictions peuvent être classées selon un ou plusieurs critères de classement avant d’être présentées pour aider l’utilisateur à compléter la requête.
Présentation d’une suggestion de recherche
Lorsqu’un chercheur saisit une requête de recherche, son entrée est surveillée.
Avant que le chercheur ne signale qu’il a terminé la saisie de la requête, une partie de la requête est envoyée au moteur de recherche.
De plus, des données telles que les données de clic (ou d’autres types d’informations collectées précédemment) peuvent également être envoyées avec la partie interrogation.
La partie de la requête envoyée peut être :
- Quelques personnages
- Un terme de recherche
- Plus d’un terme de recherche
- Toute autre combinaison de caractères et de termes
Le moteur de recherche reçoit la requête partielle et les données (par exemple, les données de clic) pour traitement et fait des prédictions) quant à la requête complète envisagée par le chercheur.
Les informations pertinentes peuvent être récupérées pour être traitées avec la requête partielle reçue afin de produire des prévisions de suggestions de recherche.
Les prévisions peuvent être classées selon un ou plusieurs critères de classement.
Ainsi, les requêtes qui ont été soumises à une fréquence plus élevée peuvent être commandées avant les requêtes soumises à des fréquences plus basses.
Le moteur de recherche peut également utiliser différents types d’informations pour le classement et l’ordre des requêtes prévues en tant que suggestions de recherche.
Les informations relatives aux requêtes de recherche précédemment saisies peuvent être utilisées pour faire des prévisions ordonnées.
Les requêtes précédentes peuvent inclure des requêtes de recherche associées au même utilisateur, à un autre utilisateur ou à une communauté d’utilisateurs.
Si l’une des requêtes prédites correspond à ce que le chercheur voulait obtenir, le chercheur peut sélectionner cette requête prédite et poursuivre sans avoir à terminer la saisie de la requête souhaitée.
Par ailleurs, si les requêtes prévues ne reflètent pas ce que le chercheur avait à l’esprit, il peut alors continuer à saisir la requête souhaitée, ce qui pourrait déclencher une ou plusieurs autres séries de suggestions de recherche.
Classement des requêtes précédentes soumises par les utilisateurs comme suggestions de recherche
Le brevet nous indique que quelques procédés différents peuvent être utilisés pour classer et ordonner les requêtes de recherche prévues :
- Les requêtes de recherche prévisionnelle peuvent être commandées selon une fréquence de soumission par une communauté d’utilisateurs
- Les contraintes de temps peuvent également être utilisées pour les requêtes de recherche classées en fonction de la dernière valeur de date/heure à laquelle la requête a été soumise
- Des informations de personnalisation ou des informations communautaires peuvent être utilisées, telles que des informations sur des sujets, des concepts ou des catégories d’informations qui intéressent l’utilisateur (à partir d’une recherche préalable ou d’informations de navigation)
- La personnalisation peut également provenir d’un groupe auquel le chercheur est associé ou auquel il appartient (un membre ou un employé).
- Selon un premier critère de classement, tel que des critères de popularité prédéfinis, puis éventuellement réordonné si l’une des requêtes de recherche prédite correspond aux informations de personnalisation de l’utilisateur, pour placer les requêtes de recherche prédite correspondantes au sommet ou plus près du sommet de l’ensemble ordonné des requêtes de recherche prédite
- Les informations fournies par le composant de suivi et le(s) journal(s) de sélection des résultats peuvent être utilisées pour classer et ordonner les requêtes de recherche prévues. (données de clic, données spécifiques à la langue et au pays).
- Les données de clics traitées (par exemple, les données de clics agrégées pour une requête donnée) pourraient être utilisées pour le classement et l’ordre des requêtes de recherche prédites – ou chaque requête un score peut être calculé en additionnant les données de clics (par exemple, les clics pondérés, etc.) sur les documents associés à la requête, et les requêtes prédites peuvent être ordonnées en fonction du score (par exemple, des valeurs plus élevées représentant mieux)
Un modèle d’information basé sur des données de requête soumises antérieurement pour obtenir des suggestions de recherche Prévisions
Ce modèle peut être utilisé pour prédire quelles données de requête pourraient satisfaire le plus un chercheur en examinant les informations de long clic. Un minuteur peut être utilisé pour suivre la durée pendant laquelle un utilisateur consulte ou « s’attarde » sur un document.
Ce temps est appelé « données de clic ».
Un temps plus long passé sur un document, serait appelé « long clic », et peut indiquer qu’un utilisateur a trouvé le document pertinent pour sa requête.
Une brève période de consultation d’un document serait qualifiée de « court clic », et peut être interprétée comme un manque de pertinence du document.
Les données de clic sont un compte de chaque type de clic (par exemple, long, moyen, court) pour une combinaison particulière de requête et de document.
Ces données agrégées de clics provenant de requêtes modèles pour un document donné peuvent être utilisées pour créer une statistique de qualité de résultat pour ce document afin d’améliorer le classement de ce document.
La statistique de la qualité des résultats peut être une moyenne pondérée du nombre de clics longs pour un document et une requête donnés.
Cette description tirée du brevet nous renseigne sur la manière dont les données de clic peuvent être stockées en tuples :
Un moteur de recherche (par exemple, le moteur de recherche) ou d’autres processus peuvent créer un enregistrement dans le modèle pour les documents qui sont sélectionnés par les utilisateurs en réponse à une requête ou à une requête partielle. Chaque enregistrement dans le modèle (ci-après dénommé « tuple ») peut être utilisé pour créer des documents : ) est au moins une combinaison d’une requête soumise par les utilisateurs, d’une référence de document sélectionnée par les utilisateurs en réponse à cette requête, et d’une agrégation des données de clic pour tous les utilisateurs qui sélectionnent la référence de document en réponse à la requête. Les données agrégées sur les clics peuvent être considérées comme une indication de la pertinence du document. Dans diverses implémentations, les données modèles peuvent être spécifiques à un lieu (par exemple, un pays, un état, etc.) ou à une langue. Par exemple, un tuple spécifique à un pays inclura le pays d’où provient la requête de l’utilisateur, tandis qu’un tuple spécifique à une langue inclura la langue de la requête de l’utilisateur. D’autres extensions des données modèles sont possibles.
Le modèle peut également inclure le comportement post-clic qui a été suivi par le composant de suivi.
Ce brevet comprend de nombreuses informations sur la manière dont Google pourrait utiliser les données de suivi des clics lors du classement des prédictions de suggestions de recherche. Il nous renseigne sur les données qui pourraient être collectées sur les clics :
Les informations recueillies pour chaque clic peuvent inclure :
(1) la requête (Q) que l’utilisateur a saisie,
(2) le résultat du document (D) sur lequel l’utilisateur a cliqué,
(3) l’heure (T) sur le document,
(4) la langue de l’interface (L) (qui peut être donnée par l’utilisateur),
(5) le pays (C) de l’utilisateur (qui peut être identifié par l’hôte qu’il utilise, tel que www-store-co-uk pour indiquer le Royaume-Uni), et
(6) les aspects supplémentaires de l’utilisateur et de la session.Le temps (T) peut être mesuré comme le temps entre le clic initial sur le résultat du document et le moment où l’utilisateur revient à la page principale et clique sur le résultat d’un autre document. En outre, on peut évaluer le temps (T) en déterminant si ce temps indique une vue plus longue ou plus courte du résultat du document, car les vues plus longues sont généralement indicatives de la qualité du résultat cliqué. Cette évaluation du temps (T) peut également être effectuée en conjonction avec différentes techniques de pondération.
Au-delà des longs clics
On nous dit également que les vues des documents sélectionnés peuvent être pondérées en fonction des informations sur la longueur de visualisation pour produire des vues pondérées du résultat du document.
Ainsi, plutôt que de simplement distinguer les clics longs des clics courts, il est possible d’inclure une gamme plus large de durées de visualisation des clics dans l’évaluation de la qualité des résultats, où les durées de visualisation plus longues dans la gamme ont plus de poids que les durées de visualisation plus courtes.
Suggestions de recherche prévisionnelle
Google affiche parfois des suggestions de recherche en utilisant la saisie semi-automatique et en se basant également sur les données des requêtes précédentes d’un chercheur ou sur l’historique d’une personne à laquelle le chercheur peut être associé, comme un collègue de travail ou un membre d’une organisation.
Alors que les résultats liés à ces précédentes requêtes ont été classés en fonction de critères tels que la pertinence et les liens, les suggestions de recherche peuvent inclure des résultats sur lesquels les chercheurs ont passé de longs clics, y compris des temps de visualisation longs.
Ainsi, en vertu de ce brevet, les prédictions concernant les suggestions de recherche choisies à l’aide de la saisie automatique peuvent mieux répondre aux besoins d’information d’un chercheur en étant des recherches qui incluent des résultats dont on se souvient qu’ils entraînent de longs clics et de longs temps de visualisation.
Article traduit librement depuis Suggestions de recherche à partir de requêtes précédemment soumises par les chercheurs